| Jun 2018 Issue 7 | ||||||
 |
||||||
|
|
| Research | |||||||||
| Development of the CUHK Dysarthric Speech Recognition System: Assistive Technology for Healthy Aging | |||||||||
|
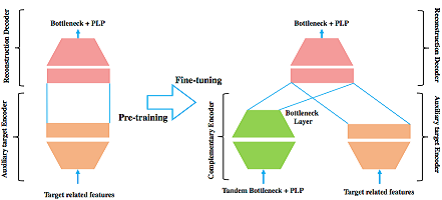
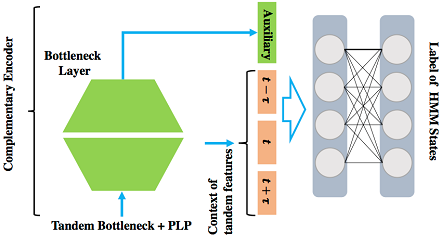
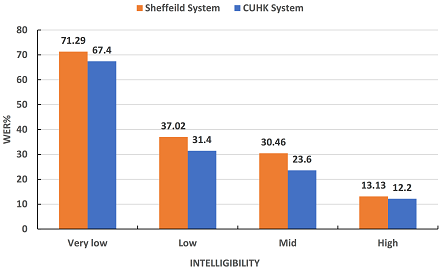
Prof. Xunying LIU, Department of Systems Engineering and Engineering Management Background As part of the ageing process, communication disorders such as dysarthria and aphasia are commonly found among the elderly population. They introduce a negative impact on their quality of life, for instance, when requiring regular health care and in-home aid. Hong Kong is a rapidly ageing society. Statistics indicate the proportion of elderly aged 65 and above is projected to rise sharply to 27% by 2033. There is a pressing need to produce new technology that can provide a natural speech-based communication interface for the elderly and other age groups who suffer from communication disorders. Problems and Challenges Dysarthria is a common type of speech disorder associated with neuro-motor conditions. The wide-ranging causes of dysarthria include neurological conditions such as Parkinson's disease, amyotrophic lateral sclerosis, or cerebral palsy, and brain damage resulting from stroke or head injuries. Dysarthria results in a loss of control of speech articulators when speaking. This produces a large mismatch against normal speech. Current state-of-the-art speech recognition systems constructed using normal speech are unsuitable to be directly employed. For example, two state-of-the-art speech recognition systems, which were developed at CUHK and can correctly recognize over 92% of the words of North American English TV or radio broadcasts and conversational telephone speech, gave a very low recognition accuracy rate of 15% when used to recognize dysarthric English speech. An initial research and development effort at the Faculty of Engineering of the Chinese University of Hong Kong was made to construct an automatic speech recognition system for the Universal Access Speech (UASpeech) database. This is currently the largest database publicly available that has been designed for English dysarthric speech. The UASpeech corpus is comprised of 16 dysarthric speakers of mixed gender. Thirty hours of speech were used in system training and another 9 hours of data were used as the test set. The loss of articulatory muscle control produces a large mismatch between dysarthric and normal speech. This also introduces a large variation among dysarthric speakers of different levels of disorder severity. In order to handle data variability, a novel recurrent neural network (RNN)-based clustering scheme was proposed in our recent research to learn both the standard frame level latent Dirichlet allocation (LDA) cluster labels and their correlation over time. An alternative approach that we developed to handle this problem used a novel semi-supervised complementary auto-encoder (CAE) based feature extraction method to automatically learn the acoustic variability encoding, as shown in the figure below. The CAE bottleneck features were learnt in a semi-supervised fashion and used in DNN acoustic model training and test time. Current System Performance The final combined system yielded an overall word recognition error rate of 30.6% on the 16-speaker UASpeech disordered speech recognition test set. To the best of our knowledge, the best previously published system for this task was developed by Sheffield University in the UK. In comparison with this Sheffield University system, our CUHK system improved the recognition performance by a statistically significant margin of 12.1% in word error rate (WER) reduction. The main improvements obtained over the Sheffield system are found in the three most challenging very low to medium low intelligibility subsets, as shown in the figure below. Future System Development toward Commercial Applications We are currently further improving the system for disordered English speech, as well as constructing similar systems for Cantonese and Mandarin for further hospital and care home trials. One exemplary application product that can be made in future research and development work is a trilingual Intelligent home environment control system. Such a product will provide users with personalized adaptive speech and language technologies that will allow them to interact with a virtual home aid system using a natural Cantonese, Mandarin or English speech based interface. This will integrate the disordered speech recognition, understanding and generation augmented with personalized system adaptation under a user-centered technical framework. More Information [1] Xurong XIE, Xunying LIU, Tan LEE and Lan WANG, "RNN-LDA Clustering for Feature-Based DNN Adaptation", in Proc. ISCA INTERSPEECH2017, Stockholm, Sweden. |
|
||||||||
|
|
|||||||||
 |
|||||||||
|
|
|||||||||||||||||||||||

