| May 2016 Issue 1 | ||||||
 |
||||||
|
|
| Research | |||||
| Research and Development: Image Super-Resolution by Deep Learning |
|||||
|
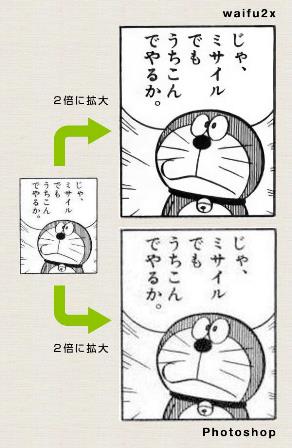
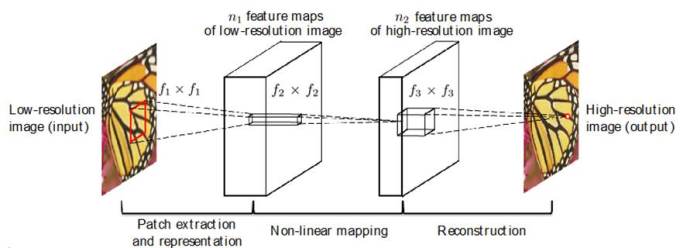
Chen-Change LOY, Department of Information Engineering, CUHK By employing a joint optimisation approach on a deep convolutional neural network model, the research team harnesses the power of deep learning to develop a state-of-the-art method for single image super-resolution. Waifu2x, a project on GitHub, gained widespread attention during the summer last year. It recorded over 10,000 retweets in Twitter and 10,000 reposts in Weibo. The project comes with an online demo [1] that allows users to upload a low-resolution image and upscale it up to 2 times of its original resolution. Amazingly, the returned image enjoys much higher quality with sharp and pristine lines than that generated by Photoshop's upscaling function. While most users apply the technique to super-resolve wallpapers and anime images (as shown in Figure 1), some users such as John Resig, the creator of the jQuery JavaScript library, found it practically useful for upscaling his Japanese wood print collection, which usually appears in tiny images [2]. The technology behind waifu2x is deep learning-based image super-resolution, a new technique developed by the Department of Information Engineering, Chinese University of Hong Kong. The team consists of Chao DONG, Chen-Change LOY, Xiaoou TANG from Multimedia Laboratory (http://mmlab.ie.cuhk.edu.hk/), and Kaiming HE from Microsoft Research. Their findings were published in the IEEE Transactions [2] in 2015. What is image super-resolution? Single image super-resolution aims at recovering a high-resolution image from a single low-resolution image. It transcends the inherent limitations of low-resolution imaging system, thus allowing better utilisation of the growing abundance of high-resolution displays. This is where the word "super" in super-resolution comes from. Image super-resolution is essential in many applications such as increasing the fidelity of medical and satellite images, where diagnosis or analysis from low-quality images can be extremely difficult, or identifying important details like faces and license plates from surveillance videos. The idea of image super-resolution is certainly not new. It is a classical ill-posed problem in computer vision since a multiplicity of solutions exist for any given low-resolution pixel. A number of solutions have been proposed in the past, but none of them achieved both high reconstruction quality and practical upscaling speed. Conventional approaches such as bicubic interpolation are fast but they are incapable of recovering high-frequency details. More recent example-based approaches learn a mapping function from a large quantity of low- and high-resolution exemplar pairs. These methods provide better reconstruction quality than the bicubic interpolation approach but they require expensive optimisation on usage. Super-Resolution Convolutional Neural Network Deep learning was listed as one of the top 10 technological breakthroughs by MIT Technology Review in 2013. It has been extensively applied on many high-level vision tasks such as face verification and object detection. The team at Multimedia Laboratory CUHK exploited the latest deep learning technology to formulate a convolutional neural network that directly learns an end-to-end mapping between low- and high-resolution images. This project is one of the pioneering studies that show the potential of deep learning on low-level vision problems. The mapping is represented as a deep convolutional neural network (CNN) that takes the low-resolution image as the input and outputs the high-resolution one, as shown in Figure 2. The network has several appealing properties. First, its structure is intentionally designed with simplicity in mind, and yet provides superior accuracy compared with other state-of-the-art example-based methods. Second, with moderate number of filters and layers, the method achieves fast speed for practical online usage even on a generic CPU. The method is faster than a number of example-based methods, because it is fully feed-forward and does not need to solve any optimisation problem on usage. What's Next The team has recently formulated a new CNN that achieves 40 times speed gain over their original method published in [2], with superior restoration quality. The new technique opens the possibility to super-resolve for high-definition videos in real-time using a generic CPU. It is hoped that one will never need to watch pixelated clips on YouTube in the near future. The team is also researching a new deep learning method that can super-resolve and restore details of human faces observed under unconstrained environments. References: Project site: http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html Contributor: |
|
||||
|
|||||
 |
|||||
|
|
|||||||||||||||||||||||

